What Actually Happens After You Save Something in Truffle Journal
Truffle Journal only acts when you explicitly ask it to save, search, list, update, or share something.
ChatGPT does not get blanket access to your whole journal. The ChatGPT connection is protected with OAuth. Requests are tied to an authenticated Truffle Journal user.
Your data is encrypted in transit (TLS) and at rest (AES-256). Access is enforced per user — not just in the UI, but in the data layer too.
The mental model
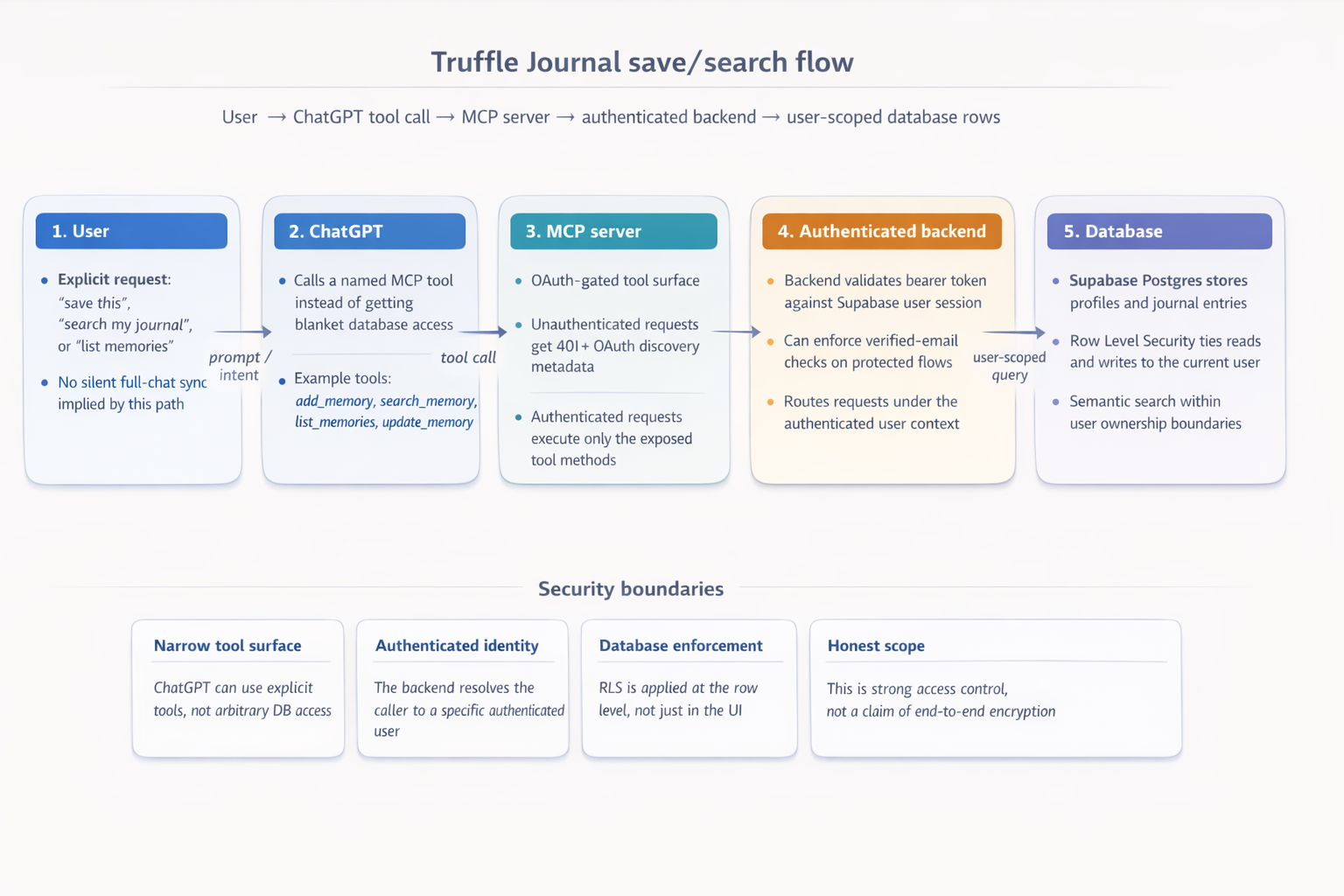
The simplest accurate model is:
You → ChatGPT tool call → Truffle Journal MCP server → authenticated backend → your journal data
That is the path to keep in mind.
The important point is not the protocol itself. The important point is that access is explicit, authenticated, and scoped.
What ChatGPT can do
When you connect Truffle Journal in ChatGPT, the integration exposes a small set of named actions.
That is very different from giving a model open-ended access to a whole database. The goal is explicit tools, not ambient browsing.
What ChatGPT cannot do by default
ChatGPT does not automatically roam through your entire journal in the background.
It does not get broad "see everything forever" access just because you connected the app.
A save or search should happen because you asked for a save or search. That distinction matters.
What gets stored
When you save something to Truffle Journal, the system may store:
The point is not to save everything that happened in a chat. The point is to save the part you wanted to keep.
What stays editable
You can edit the parts that are yours to shape: comments, tags, reminders, and organization.
Today, we intentionally treat the saved AI excerpt more like a snapshot than a freeform note. A saved entry should remain a trustworthy record of what was actually saved at that moment.
What may be sent to external AI providers
Some assistant-style workflows necessarily involve external AI systems. If you ask an assistant to remember something, search your journal, or help organize something you saved, the relevant request and the authorized excerpts needed for that action may be sent to external AI providers such as OpenAI.
The honest framing is not: "Nothing ever leaves your device."
The honest framing is: saves and searches are explicit actions, assistant access is mediated through narrow tools, requests are authenticated, access is scoped to a user, and only the relevant data for the requested action should be sent.
That is a much better trust story because it is true.
How access is protected
The point is not to make giant claims. The point is to make the access path narrow enough, and the boundaries clear enough, that you can form a sane mental model of what is happening.
Search is still bounded by ownership
Truffle Journal can support more flexible retrieval than plain keyword matching. But better search does not mean looser access.
Even when search is more semantic or context-aware, it should still stay bounded by the authenticated user's own data. Search quality and privacy boundaries are separate things. They should both hold at the same time.
Sharing
Sharing is explicit. If you choose to share something, Truffle Journal creates the share output from the entry you selected. It does not automatically publish your journal.
Beta note
Truffle Journal is still in beta. That means the UI, integrations, and product details will continue to improve. It does not mean the trust model should be vague. As the product changes, this page should stay specific.
If you have a privacy or security question, email us at hi@wonderfarm.app.
Access is explicit, authenticated, and scoped. ChatGPT gets named tools, not blanket access to your journal.
Read the plain-English version
If you care about how access, auth, search, and provider handoffs work, read the practical trust page next. It says the same thing in a less protocol-heavy way.